
Making Lucidworks Fusion Work For You: Custom Parsing and Index Pipelines
Out-of-the-box, Lucidworks Fusion® does a great many tasks remarkably well. Every now and then, however, you come across an issue that may take a little extra effort to index. What I’ll describe below, in this particular case, is a way to circumvent the Fusion parser and spin up your own custom PipelineDocument in an Index Pipeline Stage in Fusion.
So, first things first. We need to override the Fusion parser framework. We’ll do this by changing two things in our POST to the index pipeline.
First, we’ll change the Content-Type
From:
application/vnd.lucidworks-document
To:
application/octet-stream
This tells Fusion that what we’re sending is a raw stream, instead of a PipelineDocument JSON object. This is critical, because otherwise the parser will try to do something with your input, which we want to avoid in this case.
Next, we set the ‘skipParsing’ query param to ‘true’. Our POST url will then look like this:
pipelines/A_Nested_Documents/collections/_test_/index?echo=true&skipParsing=true
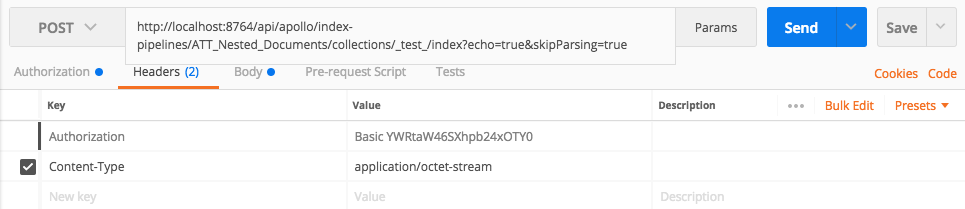
You’ll notice that I’ve also added ‘echo=true’. This means a successful result will return 200 rather than 204 (No Content). This is entirely optional. You can also “simulate=true” if you want to test — but not actually add — your documents to the collection.
Now to the code…
From the code side, the first thing you’ll want to do is create a new Index Pipeline in Fusion. You’ll give it a name (ID) and then you’ll add a JavaScript stage.
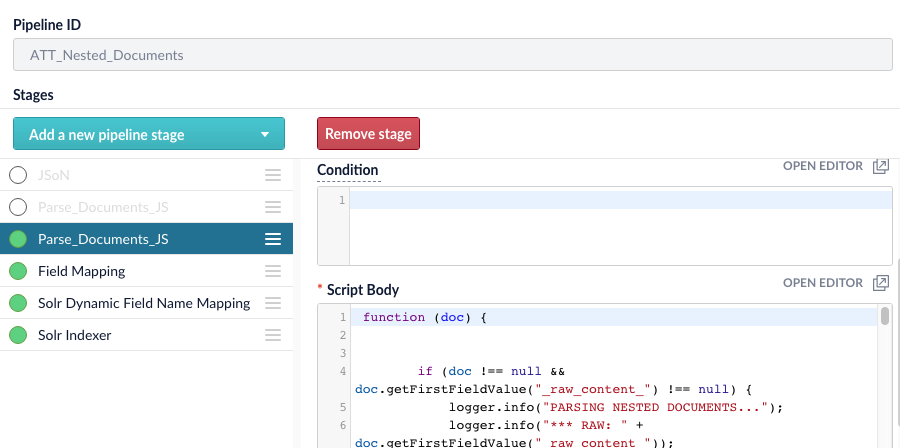
Next, you’ll want to declare the Java classes you’ll be using:
if (doc !== null && doc.getFirstFieldValue("_raw_content_") !== null) {
var ex = java.lang.Exception;
var pipelineDoc = com.lucidworks.apollo.common.pipeline.PipelineDocument;
var outdocs = java.util.ArrayList;
var ObjectMapper = org.codehaus.jackson.map.ObjectMapper;
var SerializationConfig = org.codehaus.jackson.map.SerializationConfig;
var String = java.lang.String;
var e = java.lang.Exception;
var base64 = java.util.Base64;
var String = java.lang.String;
var ArrayList = java.util.ArrayList;
var mapper = new ObjectMapper();
var pretty = true;
var result = new String(“”);
outdocs = new ArrayList();
pipelineDoc = new com.lucidworks.apollo.common.pipeline.PipelineDocument();
Notice that I check the doc for ‘null’ and check for the _raw_content_ field to be there BEFORE my declarations. This is because there is no reason to declare anything if the document isn’t there, or your content isn’t there.
try {
var rawlist = doc.getFieldValues("_raw_content_");
raw = rawlist[0];
// logger.info(“Raw class: ” + raw.getClass().getSimpleName());
// will be a byte[]
var stdin = new String(raw, “UTF8”); // turn the stream into a string.
var json = JSON.parse(stdin); // parse with the JavaScript JSON parser.
// logger.info(“JSON: ” + stdin);
mapper.configure(SerializationConfig.Feature.FAIL_ON_EMPTY_BEANS, false);
var children = json[0].fields; // get fields for the parent.
// set our PipelineDocument ID
pipelineDoc.setId(json[0].id);
logger.info(“document ID: ” + doc.getId());
Here we’re taking the UTF8 encoded byte array, and turning it into a java.lang.String, then using the native JSON parser to create a JavaScript JSON object. In this case, there was an issue with the Java Jackson JSON parser and polymorphic documents, so we wanted to avoid the parser, and handle it ourselves. At the end of it all, we set the ID for our new PipelineDocument
Now comes the heavy lifting part. We have our JSON object, and we’re going to plug it into our PipelineDocument. In this case, we’re adding child documents denoted by the “_childDocuments_” field. You can store these in a variety of ways, so you’ll want to consider that before you set out to code your project. In this instance, I’m embedding the PipelineDoucments into my parent, but you could create separate documents and bind them together using the Taxonomy API in Fusion as well, but I digress.
if (children !== null) {
/**
* Here is the heavy lifting. Now that we have a JSON object,
* We will transform it into a PipelineDocuemnt. This
* document will be fasioned after our collection schema.
*/
for (var i = 0; i < children.length; i++) {
var item = children[i];
if (item.name === “_childDocuments_”) {
// logger.info(“FOUND CHILD DOCUMENTS ! “+item.value.toString());
var cdocs = item.value;
var childArray = new ArrayList();
for (var c = 0; c < cdocs.length; c++) {
var child = cdocs[c];
var childPipeDoc = new com.lucidworks.apollo.common.pipeline.PipelineDocument();
childPipeDoc.setId(child.id);
childPipeDoc.addField(“_parent”, json[0].id);
for (var d = 0; d < child.fields.length; d++) {
var cfield = child.fields[d];
childPipeDoc.addField(cfield.name, cfield.value);
}
childArray.add(childPipeDoc);
}
pipelineDoc.addField(“_childDocuments_”, childArray);
} else {
pipelineDoc.addField(item.name, item.value);
}
}
And finally, we add our new PipelineDocument to an ArrayList, and return it. I could have also just returned the newly-created document, but for this example I wanted to demonstrate taking in a single doc, and returning multiple documents.
} catch (ex) {
logger.error(ex.getLocalizedMessage());
}
// if all goes well, we'll return our new doc right here.
logger.info("RETURN BRANCH 1");
outdocs.add(pipelineDoc);
return outdocs;
} else {
logger.info("Doc ID was null");
// if something was wrong with the doc, or it was null, we return here.
return doc;
}
// otherwise, we return here.
return doc;
}
And there it is! Your document has now been indexed into Fusion/Solr
You can find the complete code for this blog here: CustomIndexStageParsing., and sample JSON here: Nested.json
Happy Searching!
I discovered your internet site from Google as well as I have to say it was a
terrific locate. Many thanks!