
Capture Club Predictive Research Engine Architecture
We are NOT a Search Engine. We are a Research Engine.
Over the years, we have developed a fast, robust, resource-friendly, distributed framework for handling near-real-time Machine Learning and Predictive Analytics.
From a high-level, our architecture looks like this:
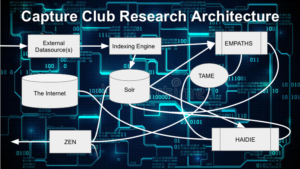
External datasources (E.g. websites, documents, file systems, etc) are ingested using our proprietary Indexing Engine, and either persisted into Solr or used for real-time Machine Learning by EMPATHS. Once an inverted index is constructed form the ingested data, HAIDIE goes to work building out dynamic classifiers. These classifiers are essentially nano-applications that have a topic, and a set of associations that are constantly re-evaluated for relevancy and priority. When a query or query profile is entered into the system, HAIDIE goes to work and provides near-real-time Machine Learning, responding to the ZEN interface via the TAME protocol. This allows for an on-going conversation, and allows the system to learn from the user.
Some of the most innovative aspects of our research engine are:
- Runs on an average AWS micro Linux instance.
- Consumes a mere 250 MB on average when running, yet still performs like a typical search engine.
- Capable of scaling out to a distributed platform to handle more intensive research requests.
- Capable of communicating with other registered tasks to distribute research tasks.
- Local database is optional.